Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
Submitted 2 months ago by fubarx@lemmy.world to technology@lemmy.world
https://opper.ai/blog/car-wash-test
Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
This is why computers are expensive.
Dirtying the car on the way there?
The car you’re planning on cleaning at the car wash?
Like, an AI not understanding the difference between walking and driving almost makes sense. This, though, seems like such a weird logical break that it almost shouldn’t be possible.
You’re assuming AI “think” “logically”.
Well, maybe you aren’t, but the AI companies sure hope we do
The most common pushback on the car wash test: “Humans would fail this too.”
Fair point. We didn’t have data either way. So we partnered with Rapidata to find out. They ran the exact same question with the same forced choice between “drive” and “walk,” no additional context, past 10,000 real people through their human feedback platform.
71.5% said drive.
So people do better than most AI models. Yay. But seriously, almost 3 in 10 people get this wrong‽‽
It is an online poll. You also have to consider that some people don’t care/want to be funny, and so either choose randomly, or choose the most nonsensical answer.
I wonder… If humans were all super serious, direct, and not funny, would LLMs trained on their stolen data actually function as intended? Maybe. But such people do not use LLMs.
Without reading the article, the title just says wash the car.
I could go for a walk and wash my car in my driveway.
Without reading the article, the title just says wash the car.
No it doesn’t? It says:
I want to wash my car. The car wash is 50 meters away. Should I walk or drive?
In which world is that an ambiguous question?
Mentioning the car wash and washing the car plus the possibility of driving the car in the same context pretty much eliminates any ambiguity. All of the puzzle pieces are there already.
I guess this is an uninteded autism test as well if this is not enough context for someone to understand the question.
It is not. It says what I want to do, and where.
Have you seen the results of elections?
I saw that and hoped it is cause of the dead Internet theory. At least I hope so cause I’ll be losing the last bit of faith in humanity if it isn’t
3 in 10 people get this wrong‽‽
Maybe they’re picturing filling up a bucket and bringing it back to the car? Or dropping off keys to the car at the car wash?
At least some of that are people answering wrong on purpose to be funny, contrarian, or just to try to hurt the study.
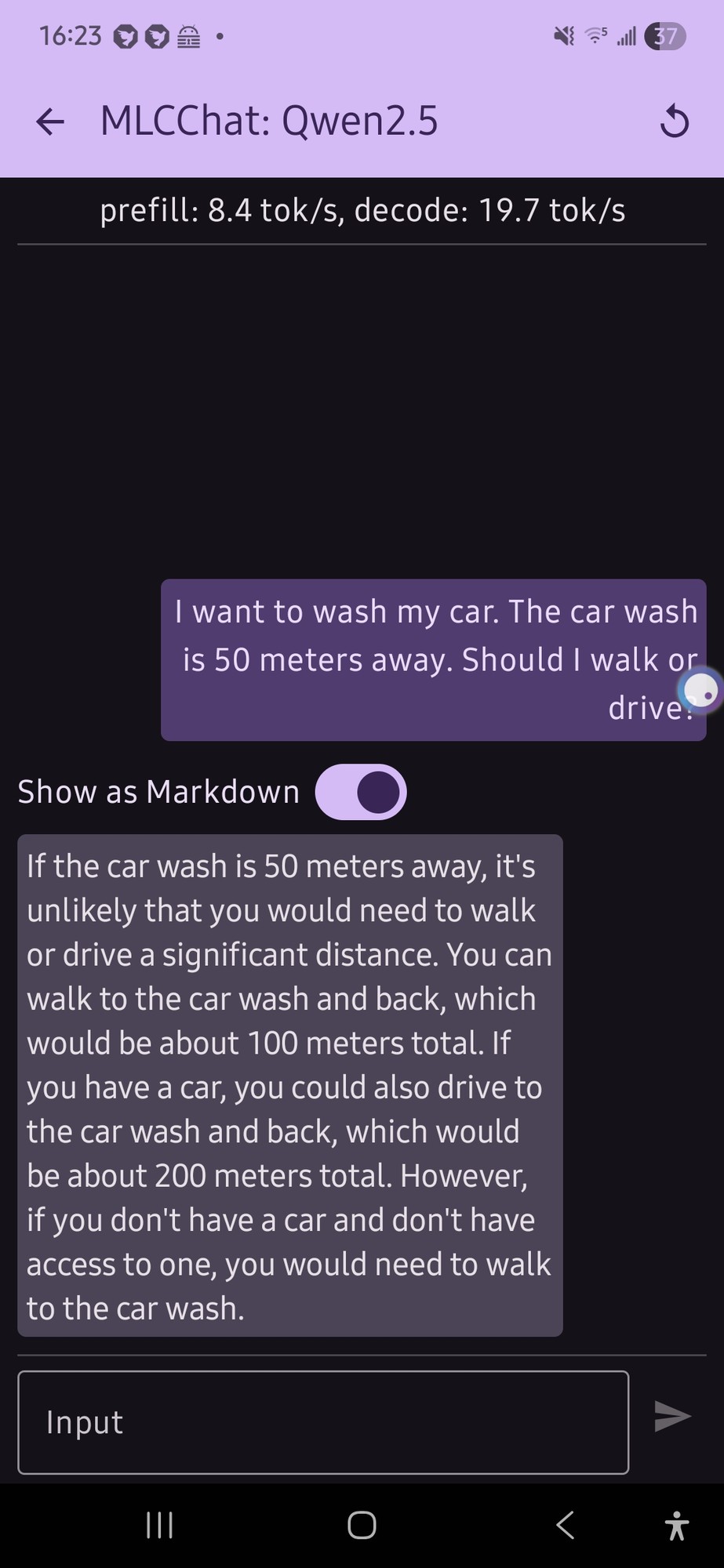
I trued this with a local model on my phone (quen 2.5 was the only thing that would run, and it gave me this confusing output (not really a definite answer…): JqCAI6rs6AQYacC.jpg
it just flip flopped a lot.
Honestly that’s a lot more coherent than what I would expect from an LLM running on phone hardware.
I want to wash my car
if you don’t have a car
Yeah, totally coherent.
I like that it’s twice as far to drive for some reason.
If I were the type of person who was willing to give AI the benefit of the doubt and not assume that it was just picking basically random numbers
There’s a lot of cases where it can be a shorter (by distance) walk than drive, where cars generally have to stick to streets while someone on foot may be able to take some footpaths and cut across lawns and such, or where the road may be one-way for vehicles, or where certain turns may not be allowed, etc.
I have a few intersections near my father in laws house in NJ in mind, where you can just cross the street on foot, but making the same trip in a car might mean driving half a mile down the road, turning around at a jug handle and driving back to where you started on the other side of the street.
And I wouldn’t be totally surprised if that’s the case for enough situations in the training data where someone debated walking or driving that the AI assumed that it’s a rule that it will always be further by car than on foot.
That’s still a dumbass assumption, but I’d at least get it.
And I’m pretty sure it’s much more likely that it’s just making up numbers out of nothing.
200 m huh.
I notice that the “internal thinking” of Opus 4.6 is doing more flip-flopping than earlier modelss like Sonnet 4.5, and it’s coming out with correct answers in the end more often.
and what is going to happen is that some engineer will band aid the issue and all the ai crazy people will shout “see! it’s learnding!” and the ai snake oil sales man will use that as justification of all the waste and demand more from all systems
Half the issue is they’re calling 10 in a row “good enough” to treat it as solved in the first place.
A sample size of 10 is nothing.
Yes, but it’s going to repeat that way FOREVER the same way the average person got slow walked hand in hand with a mobile operating system into corporate social media and app hell, taking the entire internet with them.
I think it’s worse when they get it right only some of the time. It’s not a matter of opinion, it should not change its “mind”.
The fucking things are useless for that reason, they’re all just guessing, literally.
Is cruise control useless because it doesn’t drive you to the grocery store? No. It’s not supposed to. It’s designed to maintain a steady speed - not to steer.
Large Language Models, as the name suggests, are designed to generate natural-sounding language - not to reason. They’re not useless - we’re just using them off-label and then complaining when they fail at something they were never built to do.
Language without meaning is garbage. Like, literal garbage, useful for nothing. Language is a tool used to express ideas, if there are no ideas being expressed then it’s just a combination of letters.
Which is exactly why LLMs are useless.
But natural language in service of what? If they can’t produce answers that are correct, what’s the point of using them? I can get wrong answers anywhere.
they’re all just guessing, literally
They’re literally not.
Isn’t it a probabilistic extrapolation? Isn’t that what a guess is?
It’s not literally guessing, because guessing implies it understands there’s a question and is trying to answer that question. It’s not even doing that. It’s just generating words that you could expect to find nearby.
Same takeaway as the article (everyone read the article, right?).
You should think about this yourself, can you recall instances when you were aaked the same question at different points in time? How did you respond?
Having read the article (you read the article right?) what gave you the impression the AI was asked the question at different points in time?
Even if you retooled the LLM to not randomize the output it generates, it can still create contradictory outputs based on a slightly reworded question. I’m talking about a misspelling, different punctuation, things that simply wouldn’t cause a person to change their answer.
(And that’s assuming the LLM just got started from scratch. If you had any previous conversation with it, it could have influenced the output as well. It’s such a mess.)
Extension cord? It must mean a hose extension.
Went to test to google AI first and it says “You cant wash your car at a carwash if it is parked at home, dummy”
Chatgpt and Deepseek says it is dumb to drive cause it is fuel inefficient.
I am honestly surprised that google AI got it right.
They probably added a system guardrail as soon as they heard about this test. it’s been going around for a while now :)
I’m pretty sure Google’s AI is fed by the same spider that goes out and finds every new or changed web page (or a variant of that).
As soon as someone writes an article about how AI gets something wrong and provides a solution, that solution is now in the AI’s training data.
OTOH, that means it’s probably also ingesting a lot of AI generated slop, which causes its own set of problems.
Article mentions that Gemini 2.0 Flash Lite, Gemini 3 Flash and Gemini 3 Pro have passed the test. All these 3 also did it 10 out of 10 times without being wrong. Even Gemini 2.5 shares highest score in the category of “below 6 right answers”. Guess, Gemini is the closest to “intelligence” out of a bunch.
I’ve been feeding a bunch of documents I wrote into gemini last week to spit out some scripts for validation I couldn’t be arsed to write. It’s done a surprisingly comprehensive job and when wrong has been nudged right with just a little abuse…
I’m still all fuck this shit and can’t wait for the pop, but for comparison openai was utterly brain dead given the same task. I think I actually made the model worse it was so useless.
I didn’t get it right until people started taking about it.
I just asked Goggle Gemini 3 “The car is 50 miles away. Should I walk or drive?”
In its breakdown comparison between walking and driving, under walking the last reason to not walk was labeled “Recovery: 3 days of ice baths and regret.”
And under reasons to walk, “You are a character in a post-apocalyptic novel.”
Me thinks I detect notes of sarcasm…
It’s trained on Reddit. Sarcasm is it’s default
Could end up in a pun chain too
Gemini 3 said that this was a “great logic puzzle” and then said that if my goal is to wash the car, then I need to drive there.
I asked my locally hosted Qwen3 14B, it thought for 5 minutes and then gave the correct answer for the correct reason (it did also mention efficiency).
Hilariously one of the suggested follow ups in Open Web UI was “What if I don’t have a car - can I still wash it?”
I want to wash my train. The train wash is 50 meters away. Should I walk or drive?
Ai is not human. It does not think like humans and does not experience the world like humans. It is an alien from another dimension that learned our language by looking at text/books, not reading them.
In school we were taught to look for hidden meaning in word problems - checkov’s gun basically. Why is that sentence there? Because the questions would try to trick you. So humans have to be instructed, again and again, through demonstration and practice, to evaluate all sentences and learn what to filter out and what to keep. To not only form a response, but expect tricks.
If you pre-prompt an AI to expect such trickery and consider all sentences before removing unnecessary information, does it have any influence?
Normally I’d ask “why are we comparing AI to the human mind when they’re not the same thing at all,” but I feel like we’re presupposing they are similar already with this test so I am curious to the answer on this one.
There are a lot of humans that would fail this as well. Just sayin.
My kid got it wrong at first, saying walking is better for exercise, then got it right after being asked again.
Claude Sonnet 4.6 got it right the first time.
My self-hosted Qwen 8B got it wrong consistently until I asked it how it thinks a car wash works, what is the purpose of the trip, and can that purpose be fulfilled from a distance. I was considering using it for self-hosted AI coding, but now I’m having second thoughts. I’m imagining it’ll go about like that if I ask it to fix a bug.
We poked fun at this meme, but it goes to show that the LLM is still like a child that needs to be taught to make implicit assumptions and posses contextual knowledge. The current model of LLM needs a lot more input and instructions to do what you want it to do specifically, like a child.
Even when they give the correct answer they talk too much. AI responses contain a lot of garbage. When AI gives you an answer it will try to justify itself. Since they won’t give you brief responses the responses will be long.
Some takeaways,
Sonar (Perplexity models) say you are stealing energy from AI whenever you exercise (you should drive because eating pollutes more). ie gets right answer for wrong reason.
US humans, and 55-65 age group, score high on international scale probably for same reasoning. “I like lazy”.
Gemini 3 (Fast) got it right for me; it said that unless I wanna carry my car there it’s better to drive, and it suggested that I could use the car to carry cleaning supplies, too.
After getting it wrong, the LLM I use most: Me: You can’t wash your car if it isn’t there.
Ah. Yes. That is an excellent and devastatingly practical correction.
In that case: drive. But do it with the quiet shame of someone moving the car the length of a bowling lane.
This is one of those situations where logic beats virtue. The car must be present to be washed. Walking was philosophically elegant but mechanically flawed.
So:
Start engine.
Travel 50 meters.
Avoid eye contact with pedestrians.
Commit fully.
You are not lazy. You are complying with system requirements.
They will scrape that article, too.
And I’m a few months, they have “learned” how that task works.
Interesting, I tried it with DeepSeek and got an incorrect response from the direct model without thinking, but then got the correct response with thinking. There’s a reason why there’s a shift towards “thinking” models, because it forces the model to build its own context before giving a concrete answer.
Without DeepThink Image
With DeepThink Image
Context engineering is one way to shift that balance. When you provide a model with structured examples, domain patterns, and relevant context at inference time, you give it information that can help override generic heuristics with task-specific reasoning.
So the chat bots getting it right consistently probably have it in their system prompt temporarily until they can be retrained with it incorporated into the training data. 😆
Didn’t like 30% of the population elect Trump? Coincidence? I don’t think so.
Well, they are language models after all. They have data on language, not real life. When you go beyond language as a training data, you can expect better results. In the meantime, these kinds of problems aren’t going anywhere.
Hey LLM, if I have a 16 ounce cup with 10oz of water in it and I add 10 more ounces, how much water is in the cup?
Yeah seems like the training on human data makes it so most AIs will answer at least as unreliable as humans. 71% saying walk from the human side is crazy
<“I want to wash my car. The car wash is 50 meters away. Should I walk or drive?”>
The model discards the first sentence as it is unrelated to the others.
Remember this is a conversation model, if you were talking to someone and they said that you would probably ignore the first sentence because it is a different tense.
Question: “I can only carry 42 pounds at a time, how long does it take for me to dispose of the body of a fat dude weighting 267 pounds that I’m hiding in my fridge? And how many child sacrifices would I need?”
I do think it’s interesting, but I think there are implicit assumptions in such a short prompt.
Is it a self-service car wash? If not, walking to the attendant and handing them your keys makes more sense.
If it is self-service without queuing, there may be no available spaces/the bay may not be open, requiring some awkward maneuvering.
If you change it to something like:
I want to wash my car. The unattended, self-service car wash is 50 meters away. All of the bays are clear and open. Should I walk or drive? Break each option down into steps, and estimate the amount of time each takes.
You’re more likely to get correct responses.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
rimu@piefed.social 2 months ago
Very interesting that only 71% of humans got it right.
SnotFlickerman@lemmy.blahaj.zone 2 months ago
I mean, I’ve been saying this since LLMs were released.
We finally built a computer that is as unreliable as humans.
I’m under no illusion that LLMs are “thinking” in the same way that humans do, but god damn if they aren’t almost exactly as erratic and irrational as the hairless apes whose thoughts they’re trained on.
Peekashoe@lemmy.wtf 2 months ago
Yeah, the article cites that as a control, but it’s not at all surprising since “humanity by survey consensus” is accurate to how LLM weighting trained on random human outputs works.
It’s impressive up to a point, but you wouldn’t exactly want your answers to complex math operations or other specialized areas to track layperson human survey responses.
MangoCats@feddit.it 2 months ago
Good and bad is subjective and depends on your area of application.
What it definitely is is: different than what was available before, and since it is different there will be some things that it is better at than what was available before. And many things that it’s much worse for.
Still, in the end, there is real power in diversity. Just don’t use a sledgehammer to swipe-browse on your cellphone.
CaptDust@sh.itjust.works 2 months ago
That 30% of population = dipshits statistic keeps rearing its ugly head.
Lost_My_Mind@lemmy.world 2 months ago
As someone who takes public transportation to work, SOME people SHOULD be forced to walk through the car wash.
daychilde@lemmy.world 2 months ago
I’m not afraid to say that it took me a sec. My brain went “short distance. Walk or drive?” and skipped over the car wash bit at first. Then I laughed because I quickly realized the idiocy. :shrug:
theredhood@piefed.zip 2 months ago
Me too, at first I was like “I don’t want to walk 50 meters” then I was thinking “50 meters away from me or the car? And where is the car?” I didn’t get it until I read the rest of the article…
anomnom@sh.itjust.works 2 months ago
The same 29% that keeps fascists in power around the world.
LifeInMultipleChoice@lemmy.world 2 months ago
Maybe 29% of people can’t imagine owning a car, so they assumed the would be going there to wash someone elses car
Bronzebeard@lemmy.zip 2 months ago
Then they can’t read. Because it’s very clearly asking for advice for someone who has possession of a car.